Denis Cousineau home page
Me

The PDF documents on this site were made with PrimoPDF.
Get a reader free.
![]()
The Notebook documents on this site were made with Mathematica.
Get the reader free.
![]()
Pages © Denis Cousineau;
last modified: December 17th, 2009;
page consulted on
Distribution fitting
A web page summarizing the fitting process and recent findings in this domain.
By Denis Cousineau, (c) 2007. denis dot cousineau at umontreal dotca.
The articles are available in PDF format; the notebooks are source code for Mathematica; the packages are extensions for Mathematica. All the submitted articles are draft. Check with the author to see whether they are published.
What is distribution fitting?
Definition:
Given a data set X and an assumed
theoretical distribution function f whose form depends on a set 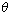 of unknown parameters, find the best-fitting parameters, i.e. the value
of the parameters which maximizes the resemblance between the theoretical
distribution and the distribution of the data in X.
of unknown parameters, find the best-fitting parameters, i.e. the value
of the parameters which maximizes the resemblance between the theoretical
distribution and the distribution of the data in X.
A number of different fitting methods exit. One group of methods involves the likelihood function. The most commonly used is the estimation by maximization of the likelihood (MLE). The MLE technique is nested in the more general Bayesian estimation technique. Further, for data sets that have been transformed into quantiles, there exists an extension to MLE which accept such data.
Another class of techniques uses the method of moments. One last class technique reduces the discrepancy between the theoretical distribution and the estimated distribution of the data using least-square techniques (see Van Zandt, 2000, PB&R), however, this approach is not recommended.
You can learn more with:
- A review of the packages that performs distribution fitting using MLE ( Article: Cousineau, Brown & Heathcote, 2004);
- A comparison of all the existing techniques ( Article: );
- A Mathematica notebook which shows how to fit a distribution ( Notebook);
- An Excel file which shows how to fit a distribution (requires Excel 2002 and above) ( Excel);
- Overview of the Bayesian estimation and Prior-informed estimation techniques ( Article: Cousineau & Hélie, submitted);
- A Mathematica package that performs Bayesian estimation and Prior-informed estimation ( Package);
- An introduction of the above package ( Notebook);
What is a convolution?
Definition: Suppose that the observed data corresponds to the sum of two internal stages (as in a two-step model). Suppose further that you know the theoretical distributions and the parameters for the two internal stages. Is it possible to infer the distribution of the observed data? This question simplifies into finding the convolution of the two theoretical distributions.
You can learn more with
- How to perform a convolution ( Notebook);
- Speeding up the fitting of a convolved distribution using approximations ( Article: Cousineau, 2004).
What is a mixture?
Definition: Suppose that the observed data corresponds to the response time to end a task. Suppose further that there exist two different strategies to end a task and that the system can use one of the strategy with probability p or the other with probability 1 p. Both strategies predict a theoretical distribution with its parameters. Is it possible to infer the distribution of the observed data? This question simplifies into finding the mixture of two distributions.
You can learn more with:
- How to get a mixture of two distributions ( Notebook);
- Fitting a mixture of (a) the distribution of lapses of attention in certain trials from (b) the distribution of regular trials ( Notebook);
- Using a mixture to separate the attentional shifts in a visual search ( Article: Cousineau & Shiffrin, 2004)
Unbiased estimation of the Weibull distribution
Definition: The Weibull distribution is now commonly used in cognitive psychology to model
the response times to complete a simple task. This distribution is a function
of three parameters, 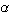 (the shift parameter),
(the shift parameter),
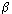 (the scale parameter) and
(the scale parameter) and 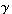 (the shape parameter).
These three parameters are distinct, each affecting only one aspect of the
theoretical distribution. However, the MLE techniques (all the cluster of
techniques) are biased in the sense that the estimated parameters are
systematically wrong. The exact amount of bias is unknown so that the estimates
cannot be corrected (unlike the sigma parameter of a normal distribution
which can be unbiased by dividing by n 1) although we know that the bias
becomes vanishingly small as the data set increases.
(the shape parameter).
These three parameters are distinct, each affecting only one aspect of the
theoretical distribution. However, the MLE techniques (all the cluster of
techniques) are biased in the sense that the estimated parameters are
systematically wrong. The exact amount of bias is unknown so that the estimates
cannot be corrected (unlike the sigma parameter of a normal distribution
which can be unbiased by dividing by n 1) although we know that the bias
becomes vanishingly small as the data set increases.
You can learn more with:
- Getting unbiased parameters for the Weibull distribution ( Article: Cousineau, D., submitted)
- A Mathematica package that returns nearly unbiased estimates ( Package)
- How to use the package ( Notebook)
Reference to the published and submitted articles
Cousineau, D. & Hélie, S. (submitted). Improving maximum likelihood estimation using prior probabilities.